
テストコードとは?必要な理由と書き方を初心者向けに解説
テストコードとは、プログラムが意図した通りに動作するかを、コードで自動的に検証する仕組みです。ブラウザを操作して画面を目で確かめる手動テストとは異なり、「この関数にこの値を渡したらこの結果が返るはずだ」という期待をコードとして書き、実行するだけで合否を即座に判定できます。
テストコードを書くことには、バグの早期発見によるコスト削減、変更後の品質を自動で確認するリグレッションテストの自動化、そしてコード設計そのものを改善する副次効果という3つの意義があります。初期導入には相応の時間がかかりますが、中長期では開発コストを下げ、品質を安定させる投資として機能します。
本記事では、テストコードの仕組みと手動テストとの違いから、単体テスト・結合テスト・E2Eテストの使い分け、AAAパターンとTDDを使った書き方の基本、そして初心者が陥りやすい3つの落とし穴と対策まで具体的に示します。
テストコードとは?プログラムの動作を自動で確かめるコード
テストコードとは、開発したプログラムが意図した通りに動作するかを、コードで自動的に検証する仕組みです。ブラウザを開いてボタンをクリックしたり、値を手で入力して画面の変化を目で確認したりするのではなく、「この関数にこの値を渡したら、この結果が返るはずだ」という期待をコードとして書き、実行するだけで合否を判定できます。
テストコードを書く意義は、次の章で詳しく扱います。まずこの章では「そもそもテストコードとは何か」「手動でのチェックと何が違うのか」を具体的な例とともに整理します。
テストコードの仕組みと役割
テストコードの基本的な流れは、入力を与えて処理を呼び出し、出力を期待値と比べるという3ステップです。
テストを実行すると、実際の戻り値と期待値を自動で比較し、一致すれば Pass(合格)、一致しなければ Fail(不合格)を即座に報告します。この判定はコンピュータが行うので、何度実行しても同じ条件・同じ基準で確認できます。
この仕組みを動かすのがテストフレームワークです。Java なら JUnit、Python なら pytest、JavaScript なら Jest といったライブラリが各言語に用意されており、期待値の比較(アサーション)やテスト結果のレポートを担います。
手動テストとの違い
手動テストには明確な強みがあります。ツールの準備が不要で、直感的にすぐ始められます。「なんとなく動作がおかしい」という感覚を手がかりに探索的に調べる場面では、人間の柔軟な判断が効果を発揮します。
しかし、コードの変更が増えるにつれて手動テストの限界が見えてきます。確認すべき箇所が増えるほど時間と人的コストが膨らみ、同じ手順を何度も繰り返すうちに見落としが起きやすくなります。また、テストした人によって確認の粒度や手順がばらつくため、再現性も保証できません。
テストコードはこの弱点を補います。一度書いてしまえば、コマンド一つで何度でも同じ条件・同じ手順を再現でき、人的ミスが入り込む余地がありません。コードを変更するたびに全テストを自動で走らせれば、意図しない箇所への影響をすぐに検出できます。
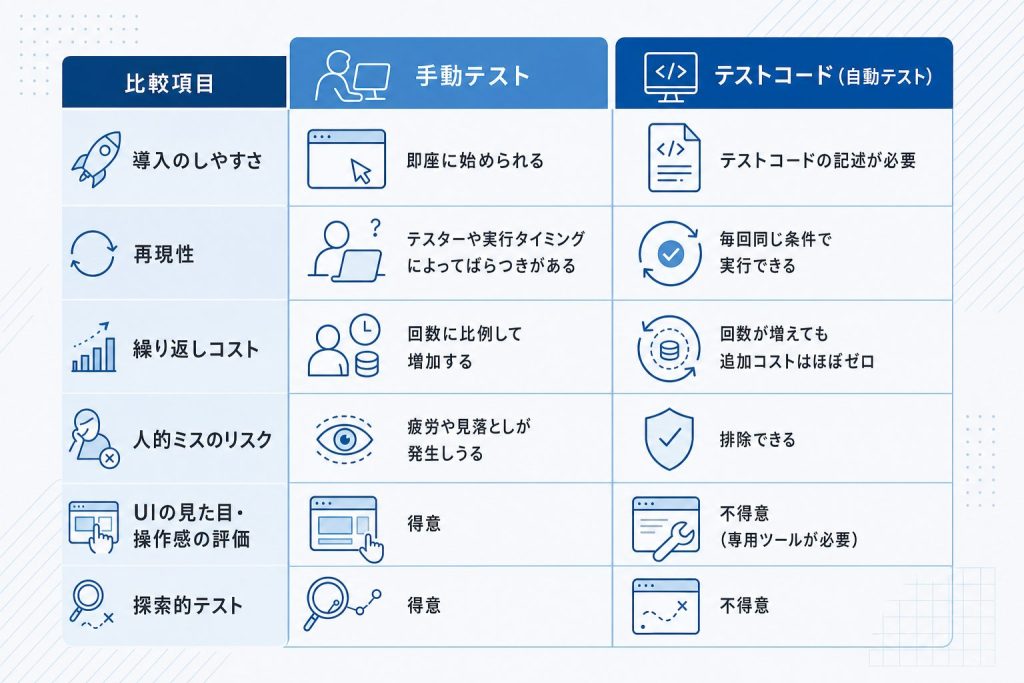
ただし、手動テストとテストコードは対立するものではありません。UIの見た目やユーザビリティ、操作感といった領域は、テストコードで自動検証するのが難しく、人間の目と感覚で確かめる方が適切です。テストコードで繰り返し検証が必要な部分を自動化し、手動テストを探索や感性が問われる場面に集中させる。この組み合わせが、実際の開発現場で機能する形です。
テスト実行時の進捗管理とテストケースの管理を見える化したい方には、テスト自動化ツール「T-DASH」と連携できるテスト管理ツール「QualityTracker」がおすすめです。
▶ テスト管理なら「QualityTracker」
テストコードを書く3つの効果と導入時の注意点
こうした手動テストとの組み合わせを前提にしたうえで、テストコードがもたらす効果を具体的に見ていきます。
ソフトウェア開発では、テスト工程が開発工数の大きな割合を占めます。IPAの調査では、新規開発における結合テストと総合テストの工数が中央値で合計32.0%に達すると報告されています(出典:IPA「ソフトウェア開発分析データ集 2022」2022年)。この数字が示すのは、テストにかかる時間をどう効率化するかが、開発全体のコスト構造を左右するという現実です。
テストコードはその効率化の中核に位置する手段であり、単なる「品質確認の仕組み」を超えた経済的な合理性を持っています。ここでは、テストコードがもつ3つのメリットを見ていきましょう。
1. バグの早期発見で修正コストを抑えられる
バグは発見が遅れるほど修正にかかるコストが跳ね上がります。Steve McConnellの著書『Code Complete』が引用するHughes Aircraftの研究では、要件定義段階で見つかったバグに比べ、システムテスト工程で発見されたバグの修正コストは約10倍になることが示されています(出典:Steve McConnell「An Ounce of Prevention」)。開発段階での修正は設計の変更範囲が狭く、コードへの影響も局所的なのに対し、結合テストやリリース後になると影響範囲の調査から始めなければならないからです。
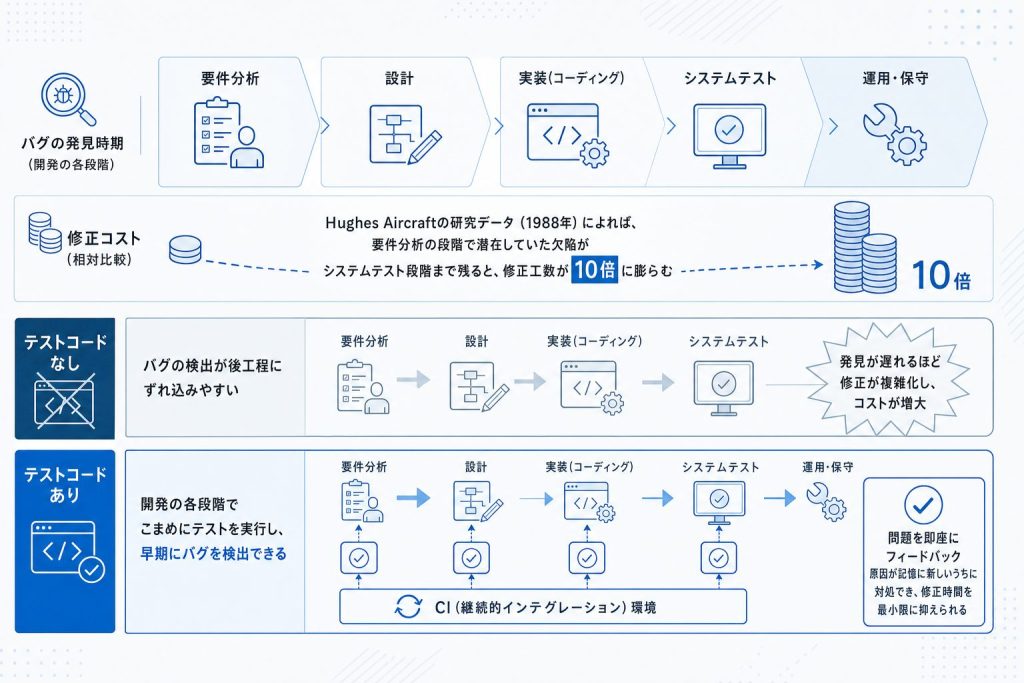
テストコードを書いて開発中にこまめにテストを実行すれば、バグをコードが新鮮なうちに発見でき、修正コストを最小限に抑えられます。「書いた直後に実行する」という習慣が、後工程での高コストな修正を根本から減らす最短経路です。
2. リグレッションテストを自動化できる
リグレッションテスト(回帰テスト)とは、機能追加やリファクタリングを行った後に、既存の機能が壊れていないかを確認するテストです。コードベースが育つにつれて確認すべき箇所は増え、手動で実施すれば数時間から数日を要することもあります。変更のたびにこの作業が繰り返されると、開発速度は着実に落ちていきます。
テストコードがあれば、コマンド一つで全テストを自動実行できます。変更後に数分でリグレッションを確認できる体制が整うため、開発者は安心してコードを変更でき、機能追加やリファクタリングの心理的なハードルも下がります。
テスト自動化はまだ普及の途上にあり、日本企業のテスト自動化率は平均33%にとどまっています(出典:Tricentis Japan 合同会社「アプリケーションモダナイゼーションとテスト自動化の現状(2024年)」2024年)。自動化率33%という現状は、テストコード導入による自動化の余地がまだ大きいことを示しており、テストコードはその自動化を実現する有力な手段の一つです。
3. コードの設計品質が改善される
テストコードを書くことには、設計そのものを改善する副次効果があります。テストを書くには、対象のコードを小さな単位に分割し、外部への依存関係を整理する必要があるからです。「このコードはテストを書きにくい」と感じる場合、それは往々にして設計上の問題を知らせるサインです。
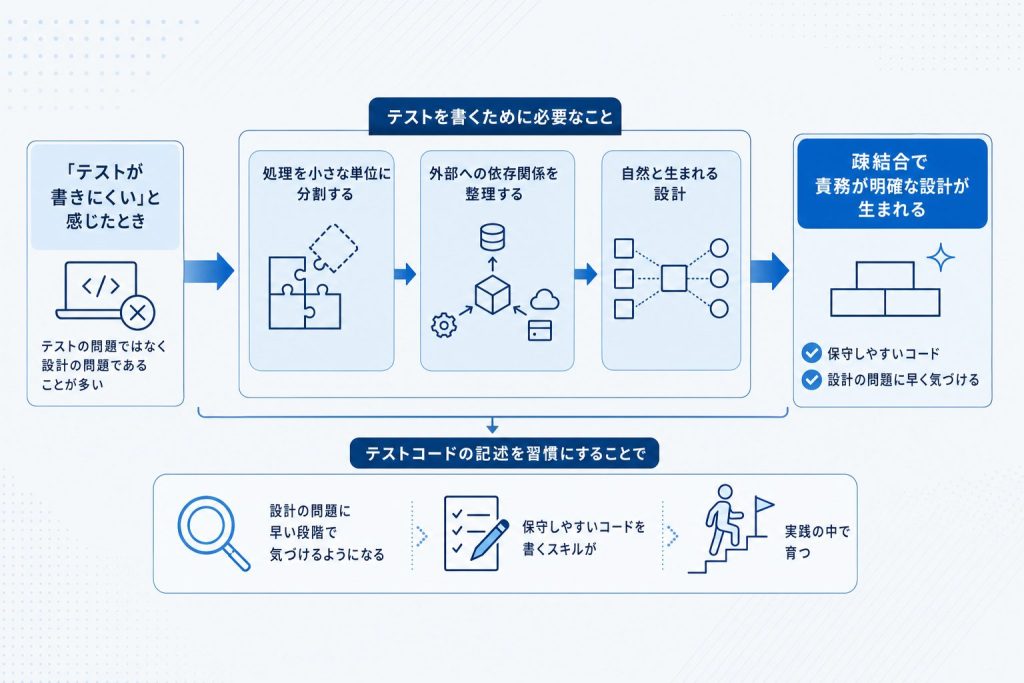
テスタブルなコードを意識するうちに、疎結合で保守しやすい設計が自然と身につきます。テストコードを書く行為は、コードの振る舞いを言語化して確認する作業でもあるため、自分が書いたコードへの理解が深まり、設計判断の質も上がっていきます。テストを書くことは、コードを書く力そのものを高める訓練でもあります。
導入時のコスト面の注意点
テストコードの導入には、率直に伝えると、相応の時間コストがともないます。テストコードの記述には本体コードと同等以上の時間がかかることがあり、導入直後は開発速度が低下すると感じる場面もあります。「工数が増える」という理由で現場への提案が通らないケースがあるのも、このコストが目に見えやすいからです。
加えて、仕様変更のたびにテストコードの修正も必要になります。本体コードを変更したのにテストコードを更新しなければ、テストは形骸化して保守負債に変わります。テストコードは「一度書けば終わり」ではなく、本体コードと並走して管理するものだという認識が必要です。
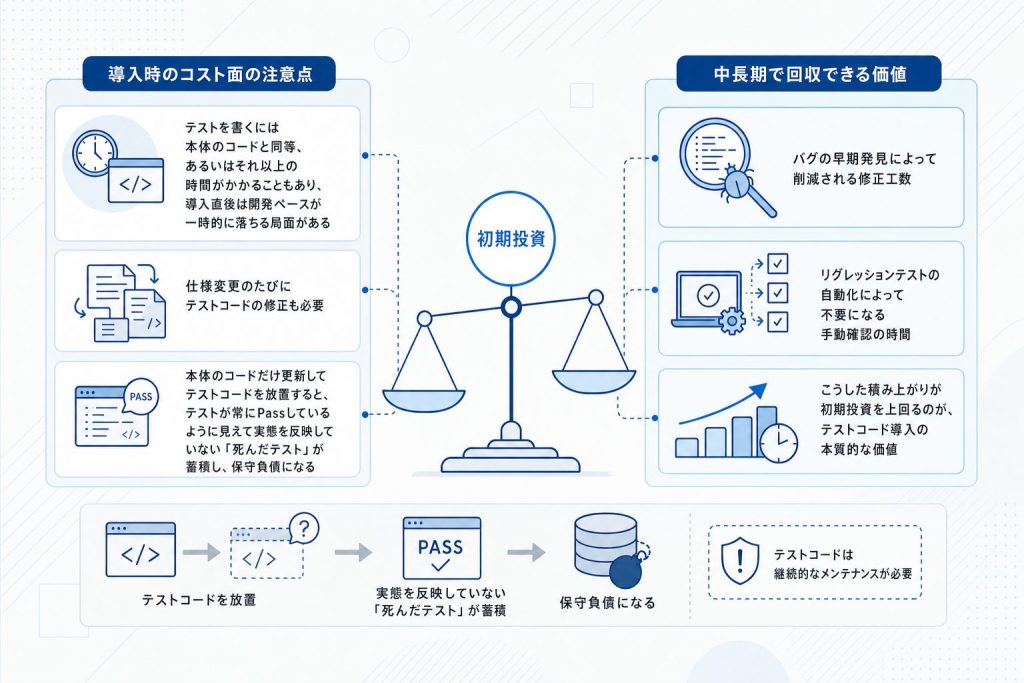
それでも中長期の視点で見ると、バグ修正の工数削減とリグレッションの自動化によって、初期コストは回収できます。短期的な速度低下を「投資の回収期間」として受け入れられるかどうかが、テストコード導入の判断軸になります。
テスト実行時の進捗管理とテストケースの管理を見える化したい方には、テスト自動化ツール「T-DASH」と連携できるテスト管理ツール「QualityTracker」がおすすめです。
▶ テスト管理なら「QualityTracker」
テストの種類とテストコードが活躍する場面
テストはテストレベルとテスト設計アプローチの2軸で整理でき、テストコードは主に下層の単体テストや結合テストで活躍します。一つ目の軸「テストレベル」は何をどこまで対象に検証するかを示し、二つ目の軸「テスト設計アプローチ」はテストケースをどの観点で設計するかを示します。
この2軸を押さえることで、テストコードがどの領域でどのように機能するのかが見えてきます。
テストレベルの分類(単体テスト・結合テスト・E2Eテスト)
テストレベルは、対象範囲の広さで3つの層に分かれます。最も小さな単位で検証する「単体テスト(ユニットテスト)」、複数のモジュールを組み合わせて検証する「結合テスト(インテグレーションテスト)」、そしてユーザーの操作を模倣してシステム全体を検証する「E2Eテスト(エンドツーエンドテスト)」の3層です。
この3層の関係は、「テストピラミッド」という概念で表されます。ピラミッドの土台が単体テスト、中間が結合テスト、頂点がE2Eテストです。上の層に行くほど対象範囲が広くなる一方、実行時間とメンテナンスコストが大きくなります。
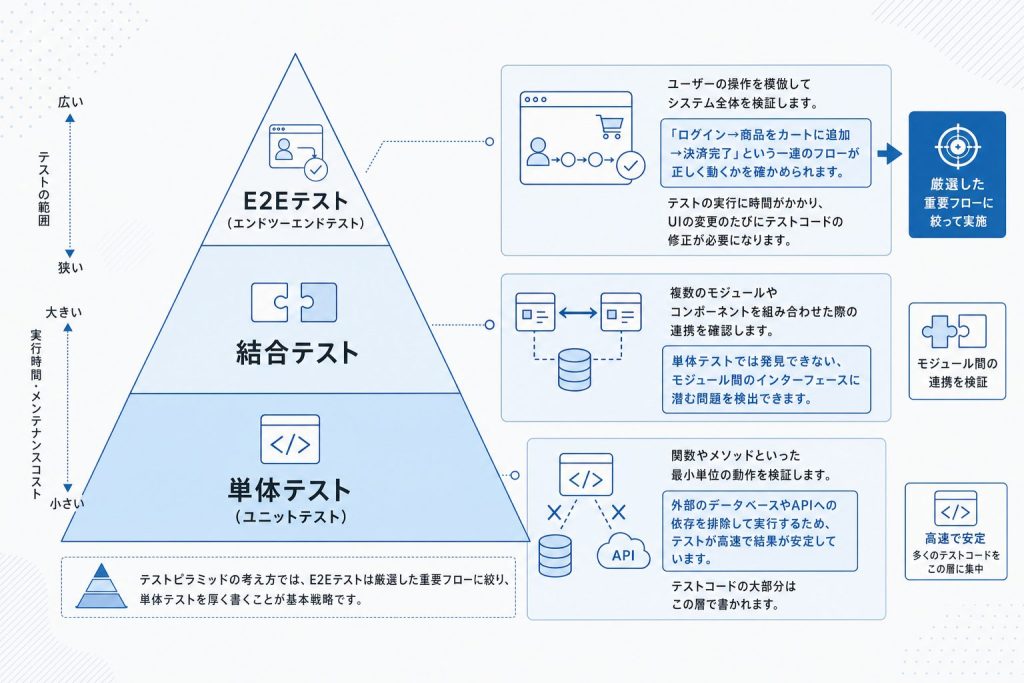
E2Eテストはブラウザやサーバーを含むシステム全体を動かすため、1回の実行に時間がかかり、UIの変更などをきっかけにテストコードが壊れやすい傾向があります。
この性質から、下層の単体テストを厚く書くのが基本戦略とされています。単体テストは関数やメソッド単位で動作を検証するため、実行が速く、問題箇所も特定しやすいというメリットがあります。テストコードが最も活躍するのも、この単体テストと結合テストの領域です。
E2Eテストは手動でのシナリオテストと組み合わせて使うことが多く、テストコードだけで完全に代替しようとするとメンテナンスの負荷が増大しがちです。
| テストレベル | 対象範囲 | 実行速度 | メンテナンスコスト | テストコードとの相性 |
| 単体テスト | 関数・メソッド単位 | 速い | 低い | ◎ |
| 結合テスト | 複数モジュールの連携 | やや遅い | 中程度 | ○ |
| E2Eテスト | システム全体・ユーザー操作 | 遅い | 高い | ○ |
テスト設計の2つのアプローチ(ブラックボックスとホワイトボックス)
テストケースをどう設計するかという観点では、「ブラックボックステスト」と「ホワイトボックステスト」の2つのアプローチがあります。両者の違いは、プログラムの内部構造を見るかどうかにあります。
ブラックボックステストは、内部の実装を知らなくても入力と出力の関係だけで検証できるアプローチです。「ある値を渡したとき、期待する値が返ってくるか」という仕様ベースの確認に向いています。代表的な設計技法としては、同値分割法(同じ結果になる入力値をグループ化する考え方)や境界値分析(上限・下限の境目付近を重点的に確認する考え方)があります。
ホワイトボックステストは、コードの内部構造を見てテストケースを設計するアプローチです。条件分岐やループが全て通過するよう網羅的にケースを作る、制御フローテストなどの技法が代表例です。単体テストでカバレッジを計測する場合には、このホワイトボックスの考え方が土台になります。
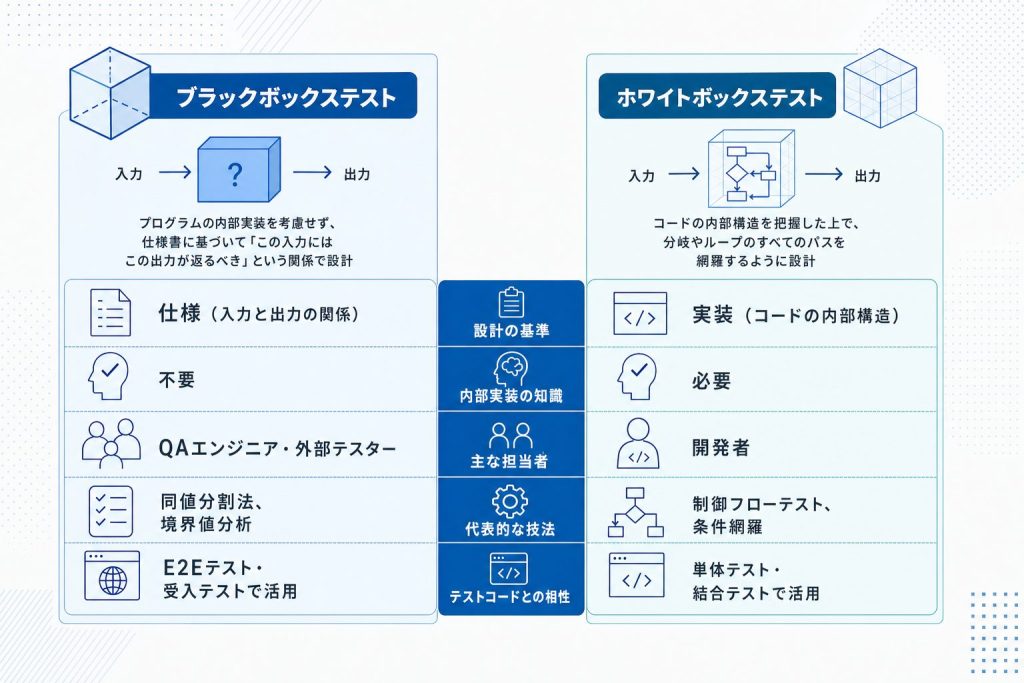
実際の開発では、両者を組み合わせて使います。仕様通りに動くかどうかはブラックボックスで確認し、実装の分岐に抜け漏れがないかはホワイトボックスで補う形です。テストコードを書く際も、まずは「この関数はこの入力でこの出力を返すべき」という仕様ベースの確認(ブラックボックス)から始め、カバレッジが気になる部分でホワイトボックスの視点を加えると、バランスよく設計できます。
テストコードの基本的な書き方
テストの種類と設計アプローチを押さえても、「実際にどう書けばいいか」の壁は別にあります。何をテストすればいいか分からず手が止まる経験をした方も多いはずです。まずは言語に依存しない共通の構造を押さえることで、どの言語・フレームワークでも応用できる書き方の軸が身につきます。
テストの基本構造(Arrange-Act-Assert)
テストコードは、Arrange(準備)→ Act(実行)→ Assert(検証)の3ステップで構成されます。この構造は「AAAパターン」と呼ばれ、言語やフレームワークを問わず広く使われている共通の設計です。
各ステップの役割を順に見ていきます。
Arrangeでは、テストに必要なデータや前提条件を揃えます。「足し算関数に整数2つを渡すテスト」なら、入力値として a = 3、b = 5 を用意する段階です。
Actでは、テスト対象の処理を実際に呼び出して結果を受け取ります。上の例なら result = add(a, b) を実行し、戻り値を変数に格納します。
Assertでは、Actで得た実際の結果が期待値と一致するかを検証します。result == 8 であれば合格、そうでなければテストは失敗します。この3段階を視覚的に示すと次のようになります。
# 疑似コード(言語非依存)
# Arrange
a = 3
b = 5
expected = 8
# Act
result = add(a, b)
# Assert
assert result == expected構造を3段階に分けて書くことには、テストを「読んだだけで何をしているか分かる」状態に保つ意味があります。Arrangeを見れば前提が分かり、Actを見れば何を確かめているかが分かり、Assertを見れば合否の基準が分かります。
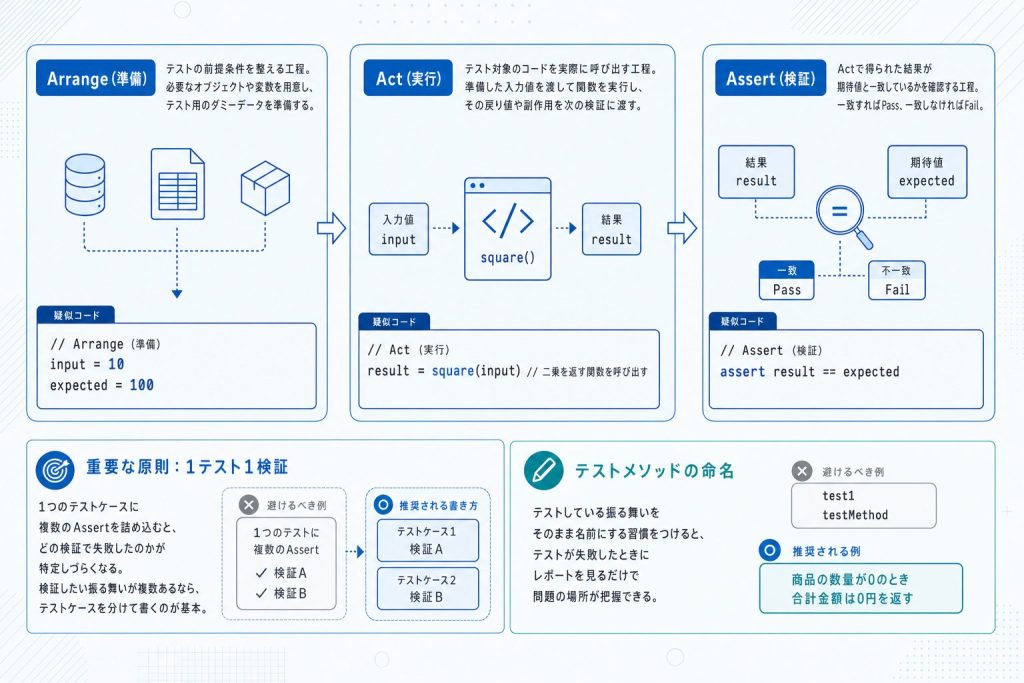
あわせて守りたいのが「1テスト1検証」の原則です。1つのテストケースでは1つの振る舞いだけを検証します。複数の検証を1つのテストに詰め込むと、テストが失敗したときに「どのAssertが落ちたのか」を追わなければならず、原因の特定に余計な時間がかかります。
検証の数だけテストケースを分けることで、失敗箇所が即座に分かる設計になります。
テスト駆動開発(TDD)の3ステップ
テストコードの書き方を学んだ次に知っておきたいのが、テストを開発プロセスにどう組み込むかです。その代表的な手法がテスト駆動開発(TDD)で、Red → Green → Refactorという3段階のサイクルで開発を進めます。
- Red(失敗するテストを書く): まだ実装していない機能に対してテストを書き、意図的に失敗させます。「失敗することを確認する」ことで、テスト自体が正しく動いていることを検証できます。
- Green(テストを通す最小限の実装をする): テストが合格するための最低限のコードだけを書きます。きれいな設計より「まず通す」ことを優先するフェーズです。
- Refactor(コードを整理する): テストが通った状態を保ちながら、重複の除去や可読性の改善を行います。テストが存在するおかげで、リファクタリング中に動作が壊れていないかをすぐ確認できます。
TDDでテストを先に書く行為には、仕様を明確にする副次的な効果があります。「この関数は空文字をどう扱うか」「引数がnullの場合はどうなるか」といった仕様のあいまいさは、実装を始めてから気づくことが多いのですが、テストを先に書く過程でこれらが浮かび上がります。結果として、実装前に仕様の漏れを潰せます。
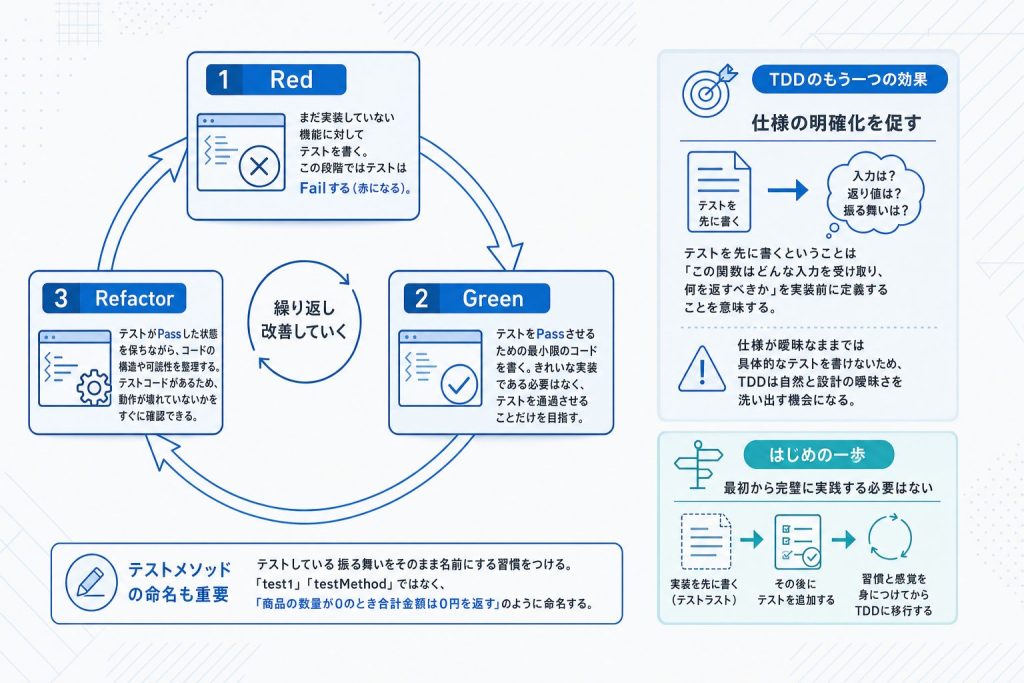
ただし、最初からTDDを完璧に実践する必要はありません。テストを先に書くという流れに慣れるまでは、まず実装後にテストを書く「テストラスト」のアプローチから始めて問題ありません。既存の関数を1つ選び、AAAパターンに沿ってテストを1本書いてみることが、最初の一歩として適切です。
テストが1本通る感覚をつかめれば、次の関数、次のテストケースへと自然に広げられます。
初心者がつまずきやすい3つの落とし穴と対策
こうした書き方の基本を身につけても、実際に書き進めると別の壁が待っています。テストコードを書き始めた初心者は、「何をテストするか」「どこまで書くか」「どう管理するか」という3つの問いに次々とぶつかります。この3点をあいまいなままにしておくと、テストが形骸化するか、逆に開発の足を引っ張る存在になります。
それぞれの問題と対策をあらかじめ知っておくことで、つまずきを回避しながら小さく書き始めることができます。
1. 何をテストすべきかわからない
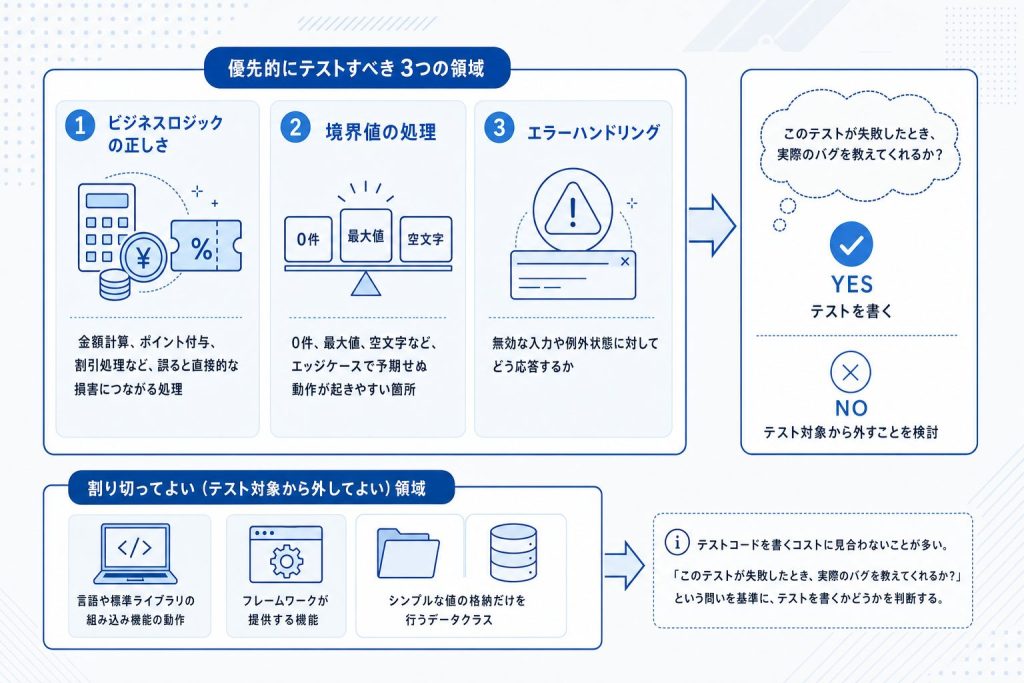
「まず何から書けばいいか分からない」という悩みは、テストコードを始めるときに最もよく聞かれます。すべての処理をテストしようとすると途方に暮れてしまいますが、優先すべき領域は3つに絞ることができます。
- ビジネスロジックの正しさ:金額計算、在庫の増減、権限の判定など、アプリケーションの「コアのルール」を担う処理。ここにバグがあると致命的なので、最初に手をつける価値があります。
- 境界値の処理:数量0、最大値、空文字など、境界付近の入力は予期しない挙動を起こしやすい箇所です。正常ケースの動作確認に加えて、境界値を明示的にテストしておくと安心できます。
- エラーハンドリング:不正な入力や例外的な状況に対して、コードが想定どおりのエラーを返すかどうかを確認します。エラー処理の漏れは本番で表面化することが多いため、早期に押さえておくべき領域です。
逆に、テストの対象外として割り切ってよい領域もあります。ボタンの色や余白といったUIの見た目は、仕様変更のたびに崩れるため手動確認に委ねる方が向いています。フレームワーク自体の動作、たとえばルーティングやORMの基本的な挙動も、すでにフレームワーク側でテストされているため自前でカバーする必要はありません。
「書かなくてよいテスト」を明確にすることで、最初の心理的ハードルを大きく下げられます。
2. テストを書きすぎてしまう
「カバレッジを上げなければ」という意識が先行すると、書くこと自体が目的になり、テストの質より量を追いかけてしまいます。カバレッジ100%を目標にすると、仕様変更のたびに大量のテスト修正が発生し、テストコード自体が開発のボトルネックになります。
省略してよいテストの典型例として、getter・setterのような値の単純な読み書きだけを行うメソッドのテストがあります。処理の分岐や計算が一切ない箇所は、テストが通ることで何かを「確かめた」とは言えないからです。同様に、フレームワークやライブラリの内部動作を間接的にテストしているだけのケースも、価値に対してコストが見合いません。
テストは量でなく、バグが起きやすい箇所に集中させることで効率が上がります。ビジネスロジックの複雑な分岐、境界値、エラーハンドリングに絞れば、少ないテストコードでも開発の安心感を確保できます。カバレッジの数値は「テストが書かれていない箇所を発見するための指標」として使い、100%自体を目的にしないことが、テストコードを長続きさせるうえで重要です。
3. テストコードの保守が追いつかない
テストを書き続けていくうち、「テストが何を確かめているのかすぐに分からない」「似たようなセットアップ処理があちこちに散らばっている」という状態になりがちです。可読性が落ちると、修正や追加のたびに既存テストを読み解く工数が増え、テストの更新を後回しにする悪循環が始まります。
対策の一つ目は、テストメソッドの命名を「何をテストしているか」が一目で分かる形にそろえることです。たとえば testCalculate() より test_割引率が0.5の場合に価格が半額になること() のように、条件と期待結果を名前に含めると、テストが壊れたときに何が起きているかを即座に把握できます。
二つ目は、テストファイルの構成を本体コードと対応させることです。UserService.java に対して UserServiceTest.java を同じ階層構造に置く、といったルールを最初から決めておくと、テストを探す手間がなくなります。
三つ目は、テストコードのリファクタリングを怠らないことです。テストコードは「一度書いたら終わり」でなく、本体コードと同じように読む人がいるコードとして扱います。各テストで繰り返されるセットアップ処理は setUp や beforeEach などの共通メソッドに切り出し、特定の入力データを作る処理はヘルパー関数にまとめることで重複を排除できます。
テストコードを整理する習慣が、保守コストを長期的に抑える土台になります。
テスト実行時の進捗管理とテストケースの管理を見える化したい方には、テスト自動化ツール「T-DASH」と連携できるテスト管理ツール「QualityTracker」がおすすめです。
▶ テスト管理なら「QualityTracker」
まとめ

テストコードとは、プログラムの動作を「コードで自動検証する仕組み」です。一度書けばコマンド一つで何度でも同じ条件で実行でき、バグの早期発見・リグレッションの自動化・設計品質の向上という3つの効果をもたらします。
初期コストはかかりますが、バグ修正の工数削減と変更時の安心感によって、中長期では開発コストを下げる投資として機能します。
テストコードの記述そのものにハードルを感じる場合は、ローコードにで日本語のテストケースをそのまま自動実行できるT-DASHという選択肢があります。月額4,840円(税込)から利用でき、30日間の無料トライアルで試せます。「テストを書きたいがコードに自信がない」という段階でも、T-DASHを使えばテスト自動化の恩恵を受けながらテストの考え方を実践で身につけることができるため、この機会にぜひ導入をご検討ください。

